In a recent project I was given the chance to design a robust and scalable pipeline for Drug labeling. In current pharmaceutical practice, the drug labeling process of taking technical documents and distilling them down to human readable labels to attach to medication is a tedious and time consuming process. To automate this task I designed an architecture that would utilize multiple AWS cloud solutions to create a robust deployment that would ensure data security and provenance. This would be accomplished by using a private blockchain ledger service called Amazon Quantum Ledger Database.

Beyond the machine learning component the interdependent cloud components needed to ensure that humans remained in the loop and that every change to label data was tracked and immutable. To ensure this process I designed a pipeline system that independently scaled Write and read Queries.
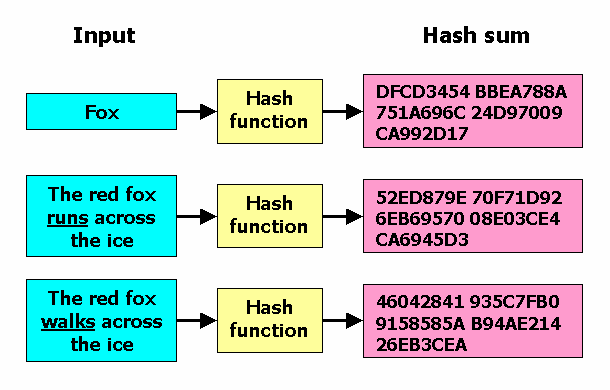
Every update on usage or drug interactions needed to be included in the most recent Label data. To ensure this I needed to make sure that only new data was used to update labels and not old. This meant that every label needed to be stored with an immutable cryptographic hash that was calculated using each label and the subsequent previous PIL’s that were used to generate said labels. This ensured that if old PIL data was submitted then during our automated analysis it would be flagged and the pipeline would be aborted.
Lastly, to ensure that pulled label data was the most up to date, each query would come from a read only database that would match query information against our immutable Amazon QLDB Ledger, this would make sure that the most up to date information was served to the end user. This read pipeline would be independently scaled using a containerized infrastructure.
With this approach, data can be exported to a graph database. Eventually this data can be dynamically mapped against a person’s biological data to generate personalized Drug labels that only hold the most pertinent information about usage. For example, if someone has had a Abdominal hysterectomy then there is no reason to add any pregnancy warnings.
